Bonjour, auriez-vous une idée de la façon dont je pourrai me débarrasser des Nan causés par la répétition d’ID svp ?
Je pense qu’il nous faut plus d’informations (comme un exemple), j’imagine que par Nan tu parle de float("NaN"), par contre la répétition d’ID ne me parle pas du tout.
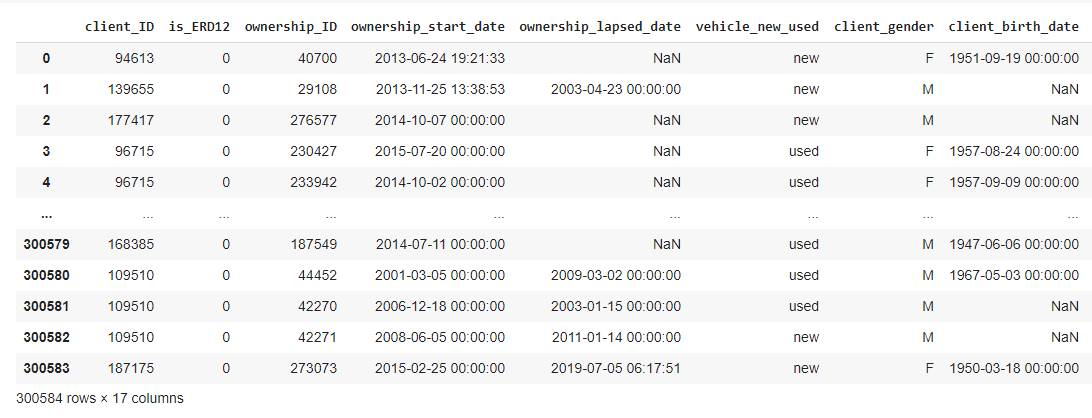
L’exemple parfait se trouve en lignes 300580 à 300582 . Pour un même ID client on a la date de naissance de ce client en ligne 300580 mais rien en lignes 300581 et 300582 . Or je souhaiterai que ce type de valeurs manquantes soient remplis par ID. L’idéal serait que le remplissage se fasse par la médiane pour les données numériques et par le mode pour les variables non numériques mais je ne sais pas quel code utilisé pour traiter ce type de valeurs manquantes.
Bonjour, c’est un pandas DataFrame ?
Créer un nouveau dataframe avec juste id , valeur puis .dropna() puis créer un nouveau DataFrame à partir de l’origial, update()é par les modifications…?
Ne jamais écraser l’original pour s’assurer de savoir retrouver ses petits…?
Je pense que tu peux t’en sortir en indexant par client_ID puis avec la fonction fillna.
>>> pd.DataFrame({"client_id": [1, 2, 3, 3], "birthdate": [datetime(2000, 1, 1), datetime(1999, 1, 1), datetime(1985, 1, 1), float('NaN')]}).set_index("client_id").fillna(method='ffill')
birthdate
client_id
1 2000-01-01
2 1999-01-01
3 1985-01-01
3 1985-01-01
1 « J'aime »
Oui ca doit marcher à condition d’avoir toujours les valeurs souhaitées dans la première ligne de chaque client - à priori il ne tient pas compte de l’index pour ffill
pd.DataFrame({"client_id": [1, 2, 3, 3], "birthdate": [datetime(2000, 1, 1), datetime(1999, 1, 1), float('NaN'), datetime(1985, 1, 1)]}).set_index("client_id").fillna(method='ffill')
birthdate
client_id
1 2000-01-01
2 1999-01-01
3 1999-01-01
3 1985-01-01Damned.
Alors j’imagine une solution mais pas très pandaesque :
>>> df = pd.DataFrame({"client_id": [1, 2, 3, 3], "birthdate": [datetime(2000, 1, 1), datetime(1999, 1, 1), float('NaN'), datetime(1985, 1, 1)]})
>>> df = df.set_index("client_id")
>>> for client_id in df.index.unique():
... df.loc[client_id].birthdate = df.dropna().loc[client_id].birthdate
...
>>> df
birthdate
client_id
1 2000-01-01
2 1999-01-01
3 1985-01-01
3 1985-01-01
Ahh OK donc :
clients = pd.DataFrame({"client_id": [1, 2, 3, 3], "birthdate": [datetime(2000, 1, 1), datetime(1999, 1, 1), np.nan, datetime(1985, 1, 1)]})
mapping = dict(clients.dropna()[['client_id', 'birthdate']].values)
clients['birthdate'] = clients.client_id.map(mapping)
clients
client_id birthdate
0 1 2000-01-01
1 2 1999-01-01
2 3 1985-01-01
3 3 1985-01-01
1 « J'aime »
Et pour la mode / moyenne / etc:
clients = pd.DataFrame({"client_id": [1, 3, 3, 3], "birthdate": [datetime(2000, 1, 1), np.nan, np.nan, datetime(1985, 1, 1)], "client_gender": ['F','M','F','M']} )
gender_mapping = dict(clients.dropna().mode()[['client_id', 'client_gender']].values)
clients['client_gender'] = clients.client_id.map(gender_mapping)