Dans le premier cas, le “ê” est un caractère à lui tout seul et dans le deuxième cas, le “ê” est une combinaison de “e” + “^” (et du coup il est compté) ?
Bravo ! Pour générer le cas j’ai utilisé unicodedata.normalize() pour passer de la « forme normale composée » (NFC) à la « forme normale décomposée » (NFD) :
>>> unicodedata.normalize("NFC", "crêpe").count("e")
1
>>> unicodedata.normalize("NFD", "crêpe").count("e")
2
Le caractère utilisé s’appelle un “caractère de combinaison” :
>>> unicodedata.name(unicodedata.normalize("NFD", "crêpe")[3])
'COMBINING CIRCUMFLEX ACCENT'
On peut faire plein de choses avec les caractères de combinaison :
>>> combining_circumflex = unicodedata.normalize("NFD", "crêpe")[3]
>>> # ou
>>> combining_circumflex = unicodedata.lookup("COMBINING CIRCUMFLEX ACCENT")
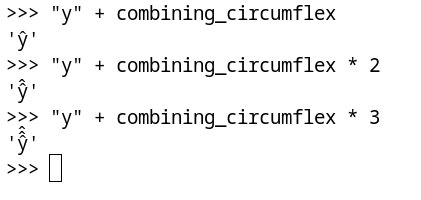
>>> "y" + combining_circumflex
'ŷ'
>>> "y" + combining_circumflex * 2
'ŷ̂'
Évidement votre navigateur ne sait pas forcément afficher sa, ou la police qu’il utilise, ou une combinaison des deux, j’imagine l’enfer que ça doit être derrière le rendu de ce genre de chose. Mais gnome-console y arrive :
Pour finir, c’est mon moyen préféré pour retirer les accents d’une chaîne :
>>> "".join(c for c in unicodedata.normalize("NFD", "pâte à crêpe") if not unicodedata.combining(c))
'pate a crepe'
[sans vergogne]Très utile pour résoudre HackInScience — Playing with anagrams[/sans vergogne].
Ah et pour finir, GG @grewn0uille, je te dois une crêpe à la prochaine PyConFR