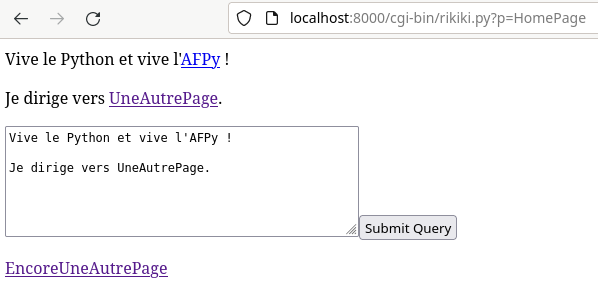
Je me suis trouvé un nouveau défi: faire un tout petit wiki.
C’est désormais chose faite : Il pourrait être “le plus petit code source de wiki du monde en python3” (laissez moi y croire 5 minutes ) avec ses 532 octets.
Il obéit à quelques contraintes de base pour tout wiki :
Génération automatique de lien : Toute chaîne de caractères en CamelCase est transformée en lien vers une nouvelle page.
Contenu éditable par tout le monde : Aucune sécurité, toute page affiche sa source qui peut être modifiée.
Contenu facilement éditable ; C’est du texte brut, hormis les sauts de ligne qui font un paragraphe et donc les liens vers les autres pages à mettre en CamelCase.
Rétro-liens : Si une page A pointe vers une page B, cette dernière affichera automatiquement un lien vers la page A.
#!/usr/bin/env python3
import cgi,json as j,re as r
p,s,c=map(cgi.parse().get,"psc")
p,o=p[0],open
s and o(p,"w").write(s[0])
o(p,"a");o("b","a")
l,k,v=j.loads(o("b").read()or"{}"),r"(([A-Z][\w]+){2})",r"<a href=?p=\1>\1</a>"
c=s[0] if s else o(p).read()
l[p]=[x[0] for x in r.findall(k,c)]
h=r.sub(k,v,c,r.M)
h=r.sub(r"\n","<p>",h,r.M)
j.dump(l,o("b","w"))
print('Content-Type: text/html\n\n%s<form method=POST><textarea name=s>%s</textarea><input type=submit></form>'%(h,c))
[n==p and print(r.sub(k,v,m)) for m in l for n in l[m]]
J’ai fait une tentative en utilisant http.server, ce qui permet de se passer d’un conteneur CGI (obsolète) pour exécuter le wiki.
Ma première version fait 657 octets, mais je pense qu’on peut améliorer les choses (il est 4h du matin, mon cerveau ne réfléchit plus assez bien), n’hésitez pas à apporter votre contribution.
Les problèmes que j’ai recontré (et potentiellement résolus au prix de plus de code) sont :
le support des encodage, http.server est assez “bas niveau” et ne gère que des bytes, obligé d’utiliser .decode() à la sortie et .encode() à la saisie, ainsi que de devoir préciser une balise <meta charset=utf-8>.
l’utilisation de urllib.parse pour parser les données du formulaire, comme c’est encore une fois assez “bas niveau” je reçois les données sous forme d’un query string que je ne peux pas enregistrer et/ou restituer tel quel.
Le script ne démarre pas tant qu’il n’y a pas au moins un fichier JSON _ contenant {} à la racine du script. J’ai essayé de réfléchir pour créer ET lire le fichier à l’entrée, mais à moins d’utiliser des try/except ou d’avoir recours à os.path.exists(), je n’ai pas trouvé de solution satisfaisante.
Voici le code minifié :
import re as r
import json as j
import http.server as h
import urllib.parse as u
d=j.load(open("_"));c="Content-"
def g(s):
s.send_response(200);s.send_header(c+"Type","text/html");s.end_headers();t=d.get(s.path,"");v=r.sub(r"/(\w+)",r"<a href=/\1>\1</a>",r.sub(r"\n","<br>",t,r.M),r.M);s.wfile.write(f"<meta charset=utf-8><p>{v}</p><form method=POST><textarea name=t>{t}</textarea><input type=submit></form>".encode())
def p(s):
d[s.path]=u.parse_qs(s.rfile.read(int(s.headers[c+"Length"])).decode())["t"][0];j.dump(d,open("_","w"));g(s)
H=type("",(h.BaseHTTPRequestHandler,),{"do_GET":g,"do_POST":p})
h.HTTPServer(("0.0.0.0",8000),H).serve_forever()
Je prends un peu plus de plomb dans l’aile avec les backlinks, je tombe à 724 octets.
Qui peut améliorer mon truc ?
import re as r
import json as j
import http.server as h
import urllib.parse as u
d=j.load(open("_"));c="Content-";a=r"/(\w+)";b=r"<a href=/\1>\1</a>"
def g(s):i=s.path;s.send_response(200);s.send_header(c+"Type","text/html");s.end_headers();t=d.get(i,"");v=r.sub(a,b,r.sub(r"\n","<br>",t,r.M),r.M);l="<br>".join(r.sub(a,b,k) for k in d if i in d[k]);s.wfile.write(f"<meta charset=utf-8><p>{v}</p><form method=POST><textarea name=t>{t}</textarea><input type=submit></form>{l}".encode())
def p(s):d[s.path]=u.parse_qs(s.rfile.read(int(s.headers[c+"Length"])).decode())["t"][0];j.dump(d,open("_","w"));g(s)
H=type("",(h.BaseHTTPRequestHandler,),{"do_GET":g,"do_POST":p})
h.HTTPServer(("0.0.0.0",8000),H).serve_forever()
import re as r,json as j,http.server as h,urllib.parse as u
d=j.load(open("_"));c="Content-";a=r"/(\w+)";b=r"<a href=/\1>\1</a>"
def g(s):i=s.path;s.send_response(200);s.send_header(c+"Type","text/html");s.end_headers();t=d.get(i,"");v=r.sub(a,b,r.sub(r"\n","<br>",t,r.M),r.M);l="<br>".join(r.sub(a,b,k) for k in d if i in d[k]);s.wfile.write(f"<meta charset=utf-8><p>{v}</p><form method=POST><textarea name=t>{t}</textarea><input type=submit></form>{l}".encode())
def p(s):d[s.path]=u.parse_qs(s.rfile.read(int(s.headers[c+"Length"])).decode())["t"][0];j.dump(d,open("_","w"));g(s)
H=type("",(h.BaseHTTPRequestHandler,),{"do_GET":g,"do_POST":p})
h.HTTPServer(("0.0.0.0",8000),H).serve_forever()
J’utilise http.server.test qui me met le hostname et le port tout seul
Je gagne qq octets a créer vraiment la classe plutôt que passer par type()
Fermer les balises HTML, pourquoi faire, le navigateur sait faire tout seul.
Un octet gagné dans la liste compréhension en collant le mot clé for.
import re as r,json as j,http.server as h,urllib.parse as u
d=j.load(open("_"))
c="Content-"
a=r"/(\w+)"
b=r"<a href=/\1>\1</a>"
def g(s):i=s.path;s.send_response(200);s.send_header(c+"Type","text/html");s.end_headers();t=d.get(i,"");v=r.sub(a,b,r.sub(r"\n","<br>",t,r.M),r.M);l="<br>".join(r.sub(a,b,k)for k in d if i in d[k]);s.wfile.write(f"<meta charset=utf-8><p>{v}</p><form method=POST><textarea name=t>{t}</textarea><input type=submit>{l}".encode())
def p(s):d[s.path]=u.parse_qs(s.rfile.read(int(s.headers[c+"Length"])).decode())["t"][0];j.dump(d,open("_","w"));g(s)
class H(h.BaseHTTPRequestHandler):
do_GET=g
do_POST=p
h.test(H)
637 octets si ça ne gêne personne que le fichier de donnée s’appelle “Content-”:
import re as r,json as j,http.server as h,urllib.parse as u
c="Content-"
d=j.load(open(c))
a=r"/(\w+)"
b=r"<a href=/\1>\1</a>"
def g(s):i=s.path;s.send_response(200);s.send_header(c+"Type","text/html");s.end_headers();t=d.get(i,"");v=r.sub(a,b,r.sub(r"\n","<br>",t,r.M),r.M);l="<br>".join(r.sub(a,b,k)for k in d if i in d[k]);s.wfile.write(f"<meta charset=utf-8><p>{v}</p><form method=POST><textarea name=t>{t}</textarea><input type=submit>{l}".encode())
def p(s):d[s.path]=u.parse_qs(s.rfile.read(int(s.headers[c+"Length"])).decode())["t"][0];j.dump(d,open(c,"w"));g(s)
class H(h.BaseHTTPRequestHandler):
do_GET=g
do_POST=p
h.test(H)
import re as r,json as j,http.server as h,urllib.parse as u
d=j.load(open("_"));c="Content-";a=r"/(\w+)";b=r"<a href=/\1>\1</a>"
def g(s):i=s.path;s.send_response(200);s.send_header(c+"Type","text/html");s.end_headers();t=d.get(i,"");v=r.sub(a,b,r.sub(r"\n","<br>",t,r.M),r.M);l="<br>".join(r.sub(a,b,k)for k in d if i in d[k]);s.wfile.write(f"<meta charset=utf-8><p>{v}</p><form method=POST><textarea name=t>{t}</textarea><input type=submit>{l}".encode())
def p(s):d[s.path]=u.parse_qs(s.rfile.read(int(s.headers[c+"Length"])).decode())["t"][0];j.dump(d,open("_","w"));g(s)
class H(h.BaseHTTPRequestHandler):do_GET=g;do_POST=p
h.test(H)
import re as r,json as j,http.server as h,urllib.parse as u
c="Content-"
d=j.load(open(c))
a=r"/(\w+)"
b=r"<a href=/\1>\1</a>"
def g(s):i=s.path;s.send_response(200);s.send_header(c+"Type","text/html");s.end_headers();t=d.get(i,"");v=r.sub(a,b,t);l=[r.sub(a,b,k)for k in d if i in d[k]];s.wfile.write(f"<pre>{l}<p>{v}</p><form method=POST><input type=submit><textarea name=t>{t}".encode())
def p(s):d[s.path]=u.parse_qs(s.rfile.read(int(s.headers[c+"Length"])).decode())["t"][0];j.dump(d,open(c,"w"));g(s)
class H(h.BaseHTTPRequestHandler):do_GET=g;do_POST=p
h.test(H)
Comment ça en 2023 un navigateur à jour privilégie latin-1 à UTF-8 ? Tristesse.
Bon bah 496 octets :
import re,json as j,http.server as h
d=j.load(open("_"))
a=r"/(\w+)",r"<a href=/\1>\1</a>"
def g(s):i=s.path;t=d.get(i,"");v=re.sub(*a,t);l=[re.sub(*a,k)for k in d if i in d[k]];s.error_message_format=f"<pre>{l}<p>{v}</p><form method=POST><input type=submit><textarea name=t>{t}";s.send_error(200)
def p(s):d[s.path]=h.urllib.parse.parse_qs(s.rfile.read(int(s.headers["Content-Length"])).decode())["t"][0];j.dump(d,open("_","w"));g(s)
class H(h.test.__defaults__[0]):do_GET=g;do_POST=p
h.test(H)